


AI on Autopilot: What Happens When No One’s Flying the Plane?
The Danger of Over-Reliance on AI and the Disappearance of Human Expertise

This post is part of the series, Exploring AI and Its Intersection with Human Decision Making. It is inspired by two I previously wrote for Psychology Today1.
You can also hear AI Matt’s summary of the piece below.

My wife and I tend to tune in to a show called Air Disasters—not the new episodes, mind you, but the block of re-runs that air on the Smithsonian Channel on Sunday afternoons. It isn’t because we’re completely enthralled with airplane crashes. It’s because the narrator, Bill Ratner, has a fantastic voice to nap to2.
Still, many of the stories are engaging and keep our attention. One episode focused on the crash of Asiana Flight 214 in San Francisco that killed 3 of the 307 people aboard and injured another 187 of them, with 49 of those injuries being serious3. The short of it, in pulling from Neuman (2014) was this:
The Boeing 777 with 307 people aboard came in too low and too slow in its landing approach, the NTSB said. It hit a seawall, ripping off the tail and sending the plane's fuselage skidding down the tarmac4.
Now, given the title of this post, it might seem as though the discussion of a plane crash would have more to do with pilot error or mechanical failure than with AI. But the lessons of Asiana Flight 214 pose several implications for the integration of advanced technologies, like AI, into human decision making.
One of the key findings of the National Transportation Safety Board’s (NTSB) investigation wasn’t just that the pilots misjudged their approach, but that they had become overly reliant on automation5. The flight crew expected the plane’s automated systems to manage the descent speed, but those systems weren’t configured the way they assumed. By the time they realized the problem, it was too late to correct it.
And so, this isn’t just a story about pilot error or a failure of the automated system—it’s about the unintended consequences of allowing technology to shape how human expertise is developed and used. The growing role of automation in aviation has dramatically improved safety, but it has also introduced new risks: the erosion of hands-on skills, overconfidence in automated systems, and a shift in the way humans interact with technology.
As AI becomes more integrated into various professions and life in general, it’s likely to have a net positive benefit for society. But at the same time, when we grow to rely too much on various AI systems, we risk something similar to what happened in that cockpit: losing the ability to recognize and respond effectively when the system doesn’t work as expected.
This leads to an important implication when it comes to decision making. While various uses of AI offer enormous benefits for human decision making, AI generally doesn’t operate error free6. Therefore, human expertise is still necessary to: (1) provide inputs in ways that increase the likelihood of generating high-quality outputs, (2) critically assess outputs produced by an AI system, and (3) compensate when an AI system fails.
Expertise as Input
Not all AI systems require the same level of user input. Some, like Google Maps, need only a few key details—your starting location and your desired destination. Assuming those inputs are correct, the AI can generate a highly accurate route with minimal effort on the user’s part.
On the other end of the spectrum, large language models (LLMs) like Claude or ChatGPT allow for near-infinite flexibility in how inputs are framed. The more open-ended the task—whether it’s generating a meal plan, drafting a legal document, or summarizing a complex issue—the more the quality of the AI’s output depends on how the user structures their input.
This variation underscores a key reality of AI-driven decision making: the more flexible the system, the more responsibility falls on the user to provide meaningful input. If inputs are vague, misleading, or incomplete, the AI will still generate a response—but it may not be useful, accurate, or relevant.
Thus, use of more flexible AI systems requires, at a minimum,
Clarifying objectives: Before AI can assist with a task, the user must know what they’re actually asking it to do. A well-defined prompt will yield far more useful results than an ambiguous request.
Structuring inputs effectively: How a question is phrased, what details are included, and how constraints are defined all influence the quality of the AI’s response.
Identifying what AI needs to know: Just as a GPS needs a valid address to generate directions, an LLM needs specific details and context to produce relevant and meaningful outputs.
This is not at all an extensive list by any means, but all three of these activities are shaped by the expertise and experience of the user. Expertise and experience are a part of the frame of reference we bring to our interactions with AI. When we lack sufficient expertise and experience, we increase the likelihood the AI will generate outputs that don’t meet our needs—or worse, produce outputs that are patently incorrect.
Expertise as Output Check
Even with well-structured inputs, AI doesn’t guarantee perfect outputs. While AI models can generate responses that appear to be reasonable, they lack a true understanding of accuracy, context, or real-world implications. This means that even high-quality inputs won’t prevent AI from occasionally producing misleading, incomplete, or outright false outputs.
More importantly, it’s not always clear why AI produced a particular output. In the case of an LLM, an expert might be able to critique the quality of the output when the system provides enough detail to evaluate its reasoning, logic, and evidence. For example, if an AI drafts a letter of recommendation for John Smith but includes incorrect details about his accomplishments, those mistakes can be easily identified and corrected—assuming the user actually reviews the output. However, this requires actively engaging with the AI’s results rather than passively accepting them as a finished product.
But not all AI systems allow for directed user input. Some, like Google Maps or Claude, require explicit input from users to generate results—a destination or a specific query. Others, like Netflix or Amazon Prime’s recommendation algorithms, operate largely on passive inputs, analyzing your past viewing habits and ratings rather than direct engagement. While giving a movie a thumbs up or down does influence future recommendations, you’re not actively interacting with the AI in real time to find something to watch.
More passive AI systems produce outputs that are fundamentally different from those generated through direct user interaction. The less control users have over what an AI system considers, the harder it becomes to evaluate why an output was generated and whether it’s actually useful.
A good example of this issue is NarxCare, which as Szalavitz (2021) reported, is designed to “automatically identify a patient’s risk of misusing opioids” (para. 11). The system relies on machine-learning algorithms that analyze vast amounts of data—including information outside of state drug registries—to generate risk scores and visualizations (see image below for a snapshot of two examples)7 .
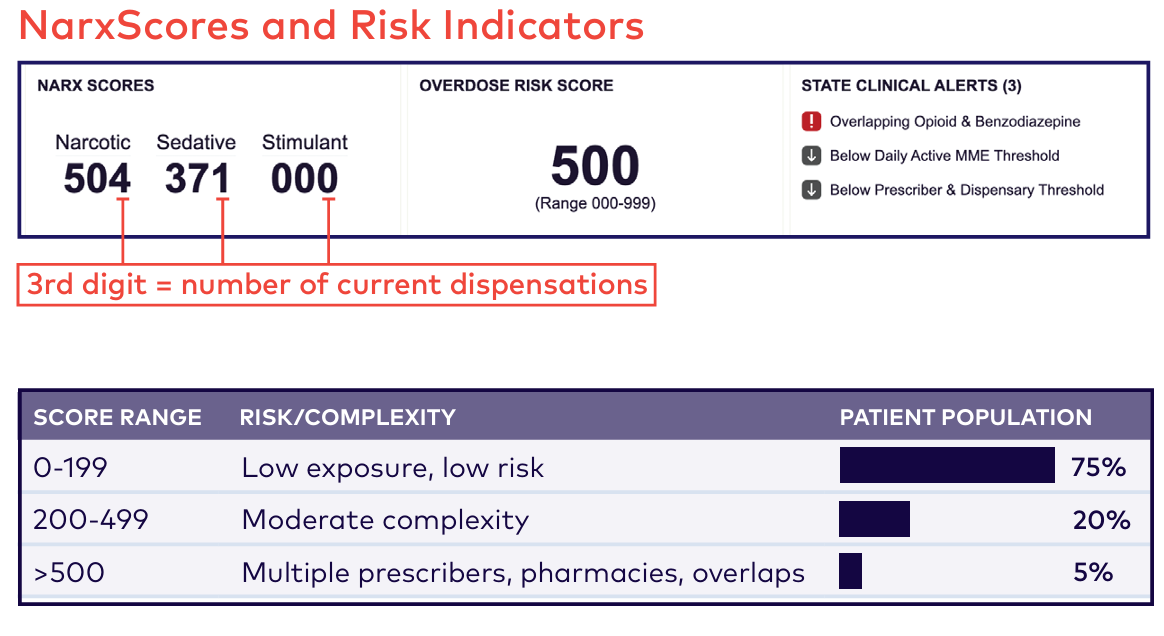
Doctors and pharmacists in states that use a system like NarcCare see a score, but they have no way of knowing how it was calculated, what data it prioritized, or whether the score is even valid. Unlike an LLM, where an expert can assess the logic of the output, NarxCare provides no transparency—making it far more difficult to challenge its recommendations.
A similar problem exists in Netflix or Amazon Prime recommendations. Whether those recommendations make sense requires active decision making on your part—just because Netflix suggests a movie doesn’t mean you’ll watch it (or even want to). And if you’ve ever scratched your head wondering why it recommended a particular film, you’ve already encountered this issue firsthand. The difference is that in low-stakes decisions like choosing a movie, errors are just an inconvenience, but in medicine, hiring, finance, and legal decisions, uncritical acceptance of AI outputs can have serious consequences.
The risk isn’t just theoretical. We’ve already seen real-world cases where blind trust in AI-generated outputs has led to serious consequences—from a professor failing his students based on a ChatGPT hallucination, to doctors defaulting to opaque risk scores that impact patient care, to lawyers including hallucinated case law in their brief, to companies using AI to make layoff decisions without human oversight. Each of these cases highlights the same issue: when AI’s outputs aren’t critically assessed, flawed decisions can follow.
And so, the role of expertise doesn’t stop at feeding AI the right inputs; it also ensures that AI’s outputs are actually useful, reliable, and appropriate for decision making. At a minimum, this requires:
Recognizing when AI has made a mistake or produced a misleading response.
Cross-referencing AI-generated information with other credible sources.
Knowing when to override or refine AI’s outputs rather than accepting them at face value.
In many situations, AI is best used as a decision-support tool, not an unquestioned authority. And in the same way that expertise helps frame AI’s inputs, it also serves as a necessary check on its outputs—ensuring that human judgment, not blind AI reliance, ultimately drives decision making.
Expertise as Compensation
Applying expertise to the evaluation of AI-generated outputs can help with overcoming many of the limitations of current AI systems. But there are times where humans offload decision making to AI, which then makes some decisions that are simply unacceptable. Human intervention is thus required to override, adjust, or fully take over the decision-making process. And while such situations aren’t common yet, they’re likely to become much more so as AI becomes more integrated into our personal and professional lives.
AI failures can occur for many reasons—sometimes because the system lacks critical context, other times because it applies rigid rules that fail in complex, real-world situations. In these cases, expertise is required not just to assess the AI’s decision but to actively step in and correct or override it. This is especially important in fields where errors carry serious consequences, such as medicine, finance, employment, and law.
Airline travel is one of those fields where AI systems have become much more integrated into standard operations. As I discussed earlier, the crash of Asiana Flight 214—though it preceded the explosion of AI into various industries—occurred, in part, because the pilots relied too heavily on automation and failed to recognize that the plane’s automated systems weren’t configured as they assumed. Had they been more actively engaged, they could have compensated for the automation’s failure by manually adjusting the aircraft’s descent. Instead, by the time they realized something was wrong, it was too late.
This highlights a key issue with AI-driven decision making: when humans become too dependent on AI systems, they may overlook when intervention is necessary. In the case of Asiana Flight 214, the pilots weren’t actively making the landing decision—the automation was. Similarly, in many industries today, AI is increasingly making autonomous decisions rather than just providing recommendations. When those decisions fail or produce unacceptable outcomes, human expertise is needed to step in, override, or adjust the system’s course.
Admittedly, there’s a blurry line between applying one’s expertise as a check of AI outputs and stepping in to correct faulty AI decision making. For example, Bhuiyan (2024) reported on a property management company that relied on a firm called SafeRent to screen potential tenants, and when the system recommended to decline a potential tenant, the tenant was declined8.
There’s also the case of the UK government relying on AI to detect benefits fraud (Booth, 2024). In fairness to the UK government, employees followed up on cases flagged by the AI, but AI-driven decisions about who to flag have led to claims of discrimination based on race, sex, and other factors. And given the seeming ubiquity with which AI is being integrated into UK governmental decision making (as reported by Booth), there’s plenty of potential for AI to make some egregious decisions.
And finally, US health insurers have faced criticism (and class action lawsuits) over the use of AI systems that were solely or chiefly responsible to approving or denying claims (Jack, 2025). Offloading the job to AI led to more efficient decision making, but such systems are (and likely never will be) 100% error proof.
This is not to say that we shouldn’t integrate AI into any of these areas. After all, the systems usually show a high degree of accuracy when used as intended. The problem exists when errors occur because there are often very real-world and sometimes severe consequences that stem from these errors.
But the problem we have is that as AI accuracy improves, there often ceases to be a need to ensure people possess the expertise necessary to override the AI’s judgment. As a case in point, far fewer people can read a map today than they could before GPS became widely available (Stechyson, 2019). And while there are perhaps few times where map reading competence would likely come into play, there’s also evidence to suggest that the more people rely on GPS, the more it erodes their internal navigation capabilities (Ishikawa, 2018; Ruginski et al., 2019).
A big reason expertise tends to fade once advanced AI systems enter the picture is that people stop developing tacit knowledge—the kind of knowledge that’s acquired through experience and practice rather than formal instruction and isn’t easily put into words. Pilots, for example, develop an intuitive sense for how an aircraft responds under different conditions—something that can’t be fully replicated by checklists or automated systems. Similarly, experienced doctors may recognize subtle symptoms of an illness that an AI diagnostic tool might miss, and seasoned fraud investigators can detect patterns of deception that don’t fit into an AI’s predefined algorithmic model.
Tacit knowledge is critical because it enables professionals to recognize when something feels off even when AI suggests otherwise. But as AI systems take on more decision-making responsibilities, opportunities to develop this type of knowledge shrink. When professionals rely too heavily on AI without staying engaged in the process, they risk losing the very judgment and intuition they’ll need when the system gets it wrong.
Wrapping Things Up
AI is becoming an increasingly valuable tool for decision making, offering efficiency, pattern recognition, and automation at a scale that human expertise alone cannot match. In some settings, it has already transformed decision making for the better: reducing errors, improving efficiency, and handling tasks beyond human capability. But even the best systems need occasional oversight—because when failures happen, expertise still matters.
And so, as AI continues to evolve and integrate into our personal and professional lives, we must recognize that technology cannot replace human judgment—it can only augment it. The challenge is not just in making AI better, but in ensuring that humans retain the skills and knowledge necessary to intervene when AI falls short. Expertise plays a role at every stage—structuring inputs to improve AI’s accuracy, evaluating outputs to verify their reliability, and stepping in to compensate when AI makes unacceptable decisions.
If we lose that balance, we risk building a world where automation works perfectly—until it doesn’t, and no one remembers how to fix it. That scenario may be extreme (and, if nothing else, still far off), but when AI makes a decision that requires human expertise to fix—and that expertise is gone—the consequences can be very real.
And although it seems exaggerated, sometimes fiction mirrors reality in ways we don’t expect9. On that note, I leave you with this clip…
It may sound weird, but he has the right calm, soothing characteristics that make napping easy. That’s not a knock against him either. He’s a fantastic narrator.
You can also read more details about it on the Wikipedia page.
You’re also welcome to read the entire 207-page report from NTSB (2013).
Some decision situations are less prone to error than others. How prone such situations are is often a function of how much uncertainty we’re talking about. For situations in which there’s little or no uncertainty (e.g., conducting basic math calculations), AI is likely to perform with little to no error. But as decision situations become more complex—and more uncertainty is introduced—AI error rates typically increase.
In my original post on this issue, I used the Kansas Board of Pharmacy example. But Kansas has switched to what it calls the K-Tracs system, which doesn’t seem to be much more transparent or obviously valid (and the decision to switch was a budgetary one).
Even though, like with NarxCare, there was no logic provided to justify the recommendation.
In fact, we can thank Idiocracy in large part for the popularity of Crocs (Kasprak, 2023; Rona & McCormick, 2024).
AI, in particular Generative AI which more popularly sees direct customer use, is not a replacement for one's thinking and judgement, it's an augmentation, and augmentation can be effective only if we have and apply the right thinking processes / skills / judgement in the first place.
Thanks Matt for the points you make here.